Dynamisches Programmieren SS09
Aus ProgrammingWiki

Autoren: Markus Ullrich - simaullr@stud.hs-zigr.de Norbert Baum - sinobaum@stud.hs-zigr.de
Inhaltsverzeichnis |
Eigenschaften
Eine Sache vorweg:
Der Begriff "Programmierung" bezieht sich in diesem Kontext nicht auf das schreiben von Code , sondern vielmehr auf eine tabellarische Methode zum Lösen von Optimierungsproblemen. Demnach sollte die Methode besser "Dynamisches Optimieren" heißen, was jedoch die traditionelle Bezeichnung nicht mehr verdrängen kann.
Im folgenden werden nun zunächst die Eigenschaften dynamischer Programmierung erläutert.
Bottom-up
Genau wie die Teile-und-Herrsche-Verfahren, löst auch die Dynamische Programmierung Probleme, durch die Kombination der Lösungen von Teilproblemen. Allerdings nutzt die dynamische Programmierung einen Bottom-up-Ansatz, bei dem alle Teillösungen "von unten her" berechnet werden. Die bereits berechneten Teillösungen werden in einer Tabelle gespeichert, womit deren erneute Berechnung entfällt. Dabei wird erwartet, dass eine optimale Gesamtlösung aus optimalen Teillösungen aufgebaut werden kann. Eine solche Lösung sollte bewusst nicht als die optimale Lösung bezeichnet werden, da es verschiedene Lösungen geben kann, die den optimalen Wert besitzen.
Schwierigkeiten
Wenn nun aus der rekursiven Beschreibung eine optimale Lösung ebenfalls rekursiv erstellt werden soll, stoßen wir auf das Problem, dass wir selten unabhängige und überlappungsfreie Teilprobleme erhalten. Das wird schon deutlich wenn wir uns die Berechnung von ansehen. Dabei müssen bei einer rekursiven Lösung erheblich viele Teilprobleme mehrfach berechnet werden. Im Bild sind diese Probleme grau hervorgehoben, ebenso wie
und
, da diese bekannte Werte sind die ohnehin nicht 'berechnet' werden müssen.
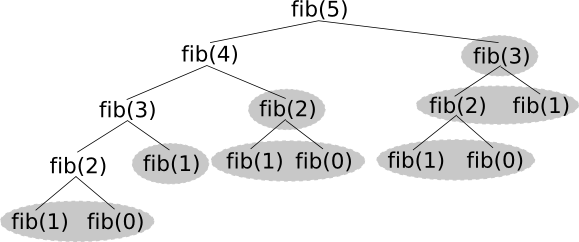

Weiterhin kann es passieren das die zu lösenden Teillprobleme unausgewogen sind. Das bedeutet, dass ein besonders schwierig zu lösendes Teilproblem den Erfolg der ganzen Methode zunichte macht. Ein populäres Beispiel vom Schach ist das Springerproblem oder auch Rösselsprung genannt. Dabei geht es darum, dass ein Springer jedes Feld auf einem beliebig großen Schachbrett genau einmal besucht. Eine mögliche Lösung unterteilt das Schachbrett in kleinere Teilrechtecke, für die spezielle Lösungen existieren. Dabei können aber verbleibende Rechtecke erheblich schwerer zu lösende Teilprobleme darstellen, zudem gewisse Anschlussbedingungen zwischen den Rechtecken realisiert werden müssen. Wer sich näher für das Problem interessiert, dem wird folgende Seite empfohlen: Springerproblem.
Da bei dynamischer Programmierung alle Teilprobleme berechnet werden kann eine sehr große Anzahl dieser ebenfalls zum Problem werden. Zudem ist nicht bei jedem Problem garantiert, dass aus der Kombination der optimalen Teillösungen eine optimale Gesamtlösung entsteht.
Überlappende Teilprobleme
Wie bereits bekannt finden wir selten Probleme, die aus unabhängigen Teilproblemen bestehen und somit eine rekursive Lösung einen erheblichen Mehraufwand betreiben würde.
Die Anwendung Dynamischer Programmierung macht jedoch vor allem in solchen Fällen Sinn, also wenn Teilprobleme ihrerseits gemeinsame Teilprobleme nutzen. Dabei entfällt die erneute Berechnung von Teilproblemen, da deren Lösungen ja in einer Tabelle gespeichert werden. Wenn man sich das Beispiel der Berechnung von ansieht, kann man sehr gut erkennen, dass somit die Berechnung von fib(n-2) komplett entfallen kann, da der Wert bereits durch die Berechnung von
bekannt ist.
Der damit eingesparte Zeitaufwand sollte dabei natürlich über dem zeitlichen Mehraufwand durch die Berechnung aller nicht benötigten Teilprobleme liegen. Das ist beim Beispiel der Berechnung der Fibonacci-Zahlen immer der Fall, da sämtliche Teilprobleme zur Berechnung benötigt werden.
Iterativ oder rekursiv?
Unseren Überlegungen zufolge wäre es also nicht von Vorteil einen rekursiven Lösungsansatz zu verwenden, da eine rekursive Lösung ineffizienter ist und somit der rekursive Lösungsansatz erst in eine iterative Lösung übertragen werden muss. Dabei ist ein erheblich hoher Denkaufwand zu leisten der somit auch in hohem Maße fehleranfällig ist.
Aber gibt es eine Möglichkeit die Effizienz einer rekursiven Lösung zu steigern, und zwar: memoizing.
Dabei werden die rekursiv berechneten Teilprobleme, wie bei einem iterativen Ansatz in einer Tabelle zwischengespeichert. Vor der Berechnung eines Teilproblems wird nun zunächst in dieser Tabelle nachgeschlagen ob bereits eine Lösung vorhanden ist. Ist dies der Fall kann die erneute Berechnung entfallen. Wenn nicht, so wird der gesuchte Wert berechnet und danach in die Tabelle eingetragen.
Somit können wir also doch einen rekursiven Lösungsansatz verwenden. Da dafür erheblich weniger Denkaufwand zu leisten ist, ist somit unsere Lösung weniger fehleranfällig.
Im folgenden werden nun iterative und rekursive Lösungen am Beispiel des bereits bekannten Rucksackproblems verglichen.
Iterative Berechnung
Von iterativer Berechnung spricht man dann, wenn ein schrittweiser Zugriff/Ablauf/Berechnung zum Einsatz kommt. Durch den Top-Down-Ansatz werden auch Teilberechnungen/Teilprobleme berechnet, die eventuell nicht benötigt werden. Aber es kommt zu keiner Mehrfachberechnung.
Beim Rucksackproblem werden die Zellen der Tabelle schrittweise ausgerechnet und befüllt, deswegen sprechen wir auch bei der ersten Lösung von der Iterativen Lösung des Rucksackproblems.
Rückkehr des Rucksackproblems
Das Rucksackproblem wurde zwar in den verschiedenen Kapiteln schon einmal angesprochen, aber wir werden es trotzdem noch einmal kurz erklären. Es ist auch unter dem Namen Knapsack problem, Transportproblem oder einfach nur Rucksack bekannt. Dabei handelt es sich um ein bekanntes Optimierungsproblem der Kombinatorik.
Der Name Transportproblem ist schon sehr gut gewählt. Das Ziel ist es, Gegenstände einzupacken/zu transportieren, wobei jeder Gegenstand ein Gewicht/Volumen und einen Wert hat. Dabei sollen die
Gegenstände so kombiniert werden, dass der Wert aller eingepackten Gegenstände maximal ist, jedoch darf das Gewicht/Volumen nicht überschritten werden.
Dieser Algorithmus oder dieses Optimierungsverfahren findet Anwendung in der Beladung von LKWs, Schiffen - überall dort, wo man einen maximalen finanziellen Gewinn erwirtschaften will.
Bei der Dynamischen Lösung des Problems sollen nun die Probleme der rekursiven Lösung behoben werden. Wie schon erwähnt, werden Teilprobleme/Teilberechnungen eventuell doppelt durchgeführt. Mithilfe der Dynamischen Optimierung/Programmierung tritt dies nun nicht mehr auf. Vor der Lösung eines Teilproblems wird erst einmal geschaut, ob dies schon geschehen ist. Wenn 'Ja', dann wird die Lösung einfach abgerufen, wenn 'Nein', dann wird der neue Wert berechnet und dann in die Tabelle eingetragen.
Die folgende Formel zeigt erst einmal die rekursive Beschreibung der Lösung:
Dimension der Tabelle
Wie schon oben erwähnt, werden die Daten in einer Tabelle gespeichert. Ohne diese ist es nicht möglich eine iterative Berechnung durchzuführen, da die aktuelle Berechnung immer Werte von vorher gegenden Berechnungen benötigt. Diese baut sich aus den Gegenständen (= Anzahl der Zeilen) und der Kapazität (= Anzahl der Spalten) auf. Dabei ist zu beachten, dass die erste Spalte und auch die erste Zeile für die Initialisierung benötigt werden.
Obwohl in der heutigen Zeit genug Speicher zur Verfügung steht, beschränken wir uns darauf, nur 2 Zeilen, nämlich die aktuelle und die vorherige Zeile zwischen zu speichern. Das liegt Nahe, da auch nur die vorhergehende Zeile zur Berechnung der aktuellen benötigt wird.
Implementation
Die Umwandlung der rekursiven in eine iterative Berechnung ist nicht so trivial wie man eventuell denkt. Zum Ausfüllen der gesamten Tabelle müssen wir die rekursive Formel in zwei verschachtelte for-Anweisungen verpacken.
Prozedur: gesamtwertIterativ Zweck: Rucksack Algorithmus zur Berechnung des maximalen Werts Parameter: int kapazitaet int-Array zeileAlt int-Array zeileNeu FOR i := 1 TO Anzahl der gegenstaende STEP 1 DO Kopiere die zeileNeu auf zeileAlt gi := das Gewicht vom dem aktuellen Gegenstand(i) FOR g := 0 TO kapazitaet STEP 1 Do wenn g < gi dann zeileNeu[g] := zeileAlt[g] //zeileNeu erhält den Wert von zeileAlt an der Postition g sonst temp := zeileAlt[g-gi] + Wert von gegenstaend[i] zeileNeu[g] := Max(temp, zeileAlt[g]) //zeileNeu bekommt den max-Wert entweder temp oder den alten wenn_ende next next Ergebnis: zeileNeu[kapazitaet] // letzte Spalte im Array steht der Maximale Wert
Da wir keine eigenen Klassen verwenden können, haben wir uns zum Darstellen der Gegenstände für Objekte vom Typ 'Point' entschieden. Dabei stellt der X-Wert das Gewicht und der Y-Wert den Wert des Gegenstandes dar. Für den schnellen Zugriff verwenden wir eine Hashmap der Form HashMap<Integer,Point>.
Es stellt sich auch die Frage, woher man weiß, mit welchen Gegenständen man den maximalen Wert erreicht hat und demnach welche man nun einpacken muss. Dies haben wir durch eine 2. Tabelle gelöst. Diese ist genauso groß wie die erste. Jedoch werden dort nicht die Werte gespeichert, sondern die Reihenfolge der Gegenstände, die eingepackt wurden. In unserem Fall werden die Gegenstandsnummern in der Tabellen-Zelle gespeichert und durch ein ';' getrennt.
Die folgende Canvas soll noch einmal die iterative Abarbeitung grafisch veranschaulichen. Man erkennt sehr gut, wie die Berechnung zeilenweise passiert und immer die vorhergehende Zeile nur Berechnung der neuen mit einbezieht. Dies ist durch das Einfärben der benutzten Werte kenntlich gemacht (leider etwas schwer ersichtlich). Das Ergebnis steht dann wie formal schon bekannt ganz unten rechts in der Tabelle. Auch in der Grafik ist dies der Fall.
Aufgrund von verschiedenen Desktopauflösungen haben wir uns auf 1024 x egal entschieden und somit wird maximal eine Kapazität von 30 gezeichnet.
Aufwandsbetrachtung
Durch die iterative Abarbeitung kann man sehr schnell erkennen, dass sich der Aufwand aus der Anzahl der Zeilen und Spalten zusammensetzt.
Fasst man als Konstante auf, so erreicht man eine uniforme Komplexität, was einen linearen Aufwand von
ergeben würde. Dies ist jedoch nicht der Fall, da aus praktischer Relevanz
und
zusammenhängen müssen und sich im Allgemeinen sogar ein exponentieller Aufwand ergibt.
Das ist darauf begründet, dass es sich bei dem Algorithmus zur Lösung des 0/1 Rucksackproblems um einen pseudopolynomialen Algorithmus handelt. Hier ist das uniforme Komplexitätsmaß nicht anwendbar, sondern wir benötigen zur Aufwandsbetrachtung die Bit-Komplexität, welche die Länge der Eingabewerte berücksichtigt.
Dazu müssen wir natürlich die Eingabelänge erst einmal feststellen. Dabei besteht die Eingabe aus natürlichen Zahlen, nämlich sämtlichen Gewicht-Werte-Paaren
und der Kapazität
in Binärdarstellung. Auf dem Band einer Turingmaschine (dem dazugehörenden theoretischen Modell) kann dabei auf einem Feld nur ein Zeichen des Eingabealphabetes stehen, also genau ein Bit.
Nun definieren wir und beschränken die Eingabelänge nach oben durch
. Lässt sich
nun in der Form
darstellen und somit
, so erhalten wir für die Eingabelänge
und es ergibt sich eine exponentielle Rechenzeit des Algorithmus mit
.
Polynomiale Rechenzeit lässt sich nur erreichen, wenn durch ein Polynom beschränkt wird, wie zum Beispiel
, womit sich eine Rechenzeit in
ergibt. Das ist jedoch, wie eingangs bereits erwähnt, im Allgemeinen nicht der Fall. Darum spricht man von einem pseudopolynomialen Algorithmus.
Rekursive Berechnung
ohne memoizing
Zunächst wollen wir einen rekursiven Algorithmus ohne memoizing implementieren. Anhand der rekursiven Beschreibung bereitet uns das auch keine Schwierigkeiten und somit kommen wir zu folgender Funktion:
Wie man sehen kann, stimmt das Ergebnis mit dem der iterativen Lösung überein. Jedoch wurden offenbar einige Elemente mehrfach berechnet, da die Zahl der rekursiven Aufrufe deutlich größer ist, als die Anzahl aller Teilprobleme.
mit memoizing
Nun wollen wir den Algorithmus durch memoizing erweitern. Für die Tabelle verwenden wir in Java eine verschachtelte Hashmap der Form HashMap<Integer,HashMap<Integer,Integer>> um schnelle Zugriffe zu gewährleisten. Damit wird die Rechenzeit nicht wesentlich durch das Abfragen der Elemente beeinflusst.
Man kann erkennen, dass wir auch mit memoizing den selben Wert erhalten wie bereits zuvor. Jedoch ist die Zahl der rekursiven Aufrufe deutlich geringer als ohne memoizing und es werden sogar weniger Teilprobleme gelöst als bei der iterativen Variante. Dort mussten ja sämtliche Tabellenelemente, also insgesamt 1331 Teilprobleme berechnet werden. Außerdem sieht man, dass die Länge der memoliste mit der Anzahl der rekursiven Aufrufe nahezu übereinstimmt. Hinzu kommt, dass bei einem erneuten Aufruf, der Algorithmus aus der bereits gefüllten Memoliste einen Vorteil ziehen kann. Da unser Ergebnis ja bereits berechnet wurde, können wir einfach darauf zugreifen und benötigen somit nur einen rekursiven Aufruf, nämlich den ersten.
Fazit
Rekursive Berechnung mit memoizing ist also mindestens genauso schnell wie iterative Berechnung. Lediglich wenn alle Teilprobleme mindestens einmal berechnet werden müssen, ist die iterative Variante gewöhnlich um einen konstanten Faktor schneller wie die rekursive Variante. Dies spielt jedoch kaum eine Rolle, da man diese konstanten Faktoren bei der Aufwandsbetrachtung auch vernachlässigen kann. Zudem werden haufig nicht alle Teilprobleme benötigt und somit sollte die rekursive Variante, die nur die benötigten Teilprobleme berechnet, natürlich bevorzugt werden. Auch schon aus dem Grund, dass diese direkt aus der rekursiven Vorschrift abgeleitet werden kann. Dadurch wird eine fehleranfällige Transformation unnötig.
Optimale Teilstruktur
Möchte man ein Problem mithilfe dynamischer Programmierung lösen, wirft sich schnell eine entscheidende Frage auf: "Wie stelle ich die optimale Teilstruktur fest, bzw. existiert diese überhaupt?"
Wie wir uns erinnern, war dies ja die Vorraussetzung dafür, dass ein Problem überhaupt mit dynamischer Programmierung lösbar ist, da die Teilprobleme ihrerseits wieder eine optimale Lösung besitzen müssen. Wir müssen also absichern, dass der Bereich der von uns betrachteten Teilprobleme die von der optimalen Lösung verwendeten einschließt.
Wir haben bereits beim Rucksackproblem die optimale Teilstruktur entdeckt, indem wir von der Annahme ausgegangen sind, dass ein optimal gepackter Rucksack aus einem bis dahin optimal gepacktem 'Teil-Rucksack' und einem weiteren hinzugefügten Gegenstand besteht. Diese Annahme lässt sich sehr leicht beweisen. Wenn der 'Teil-Rucksack' mit einer bestimmten 'Teil-Kapazität' vor dem Einpacken des nächsten Gegenstandes (der zur optimalen Lösung gehört) nämlich nicht optimal gepackt wäre, würde eine andere Lösung durch hinzufügen desselben Gegenstandes
eine bessere Lösung ergeben als die optimale. Dies ist ganz klar ein Widerspruch und somit ist unsere vorherige Annahme damit auch bewiesen.
Vorgehensweise beim Aufdecken
So wie beim Aufdecken der optimalen Teilstruktur beim Rucksackproblem, können wir auch bei anderen Problemen einem allgemeinem Muster folgen:
1. Zunächst gilt es zu zeigen, dass ein Problem gelöst wird, indem man eine Wahl trifft, wie das Finden des optimal gepackten 'Teil-Rucksacks' ("Gegenstand dazupacken oder die anderen alle drin lassen?"). Nach Treffen dieser Wahl erhält man wiederum eines oder mehrere noch zu lösende Teilprobleme.
2. Weiterhin ist anzunehmen, dass die Wahl, die zu einer optimalen Lösung führt, zu einem gegebenen Problem bekannt ist. Wie diese Wahl getroffen wird, muss noch nicht bekannt sein.
3. Daraufhin ist nun zu bestimmen, welche Teilprobleme sich ergeben, wobei der resultierende Raum der Teilprobleme am bestmöglichsten beschrieben werden muss und möglichst klein sein sollte.
4. Nun ist noch zu zeigen, dass die Teilprobleme, die innerhalb einer optimalen Lösung verwendet werden, selbst optimal sein müssen. Dazu greift man auf ein "Cut & Paste-Verfahren" zurück, bei dem man annimmt, dass keine der Lösungen eines Teilproblems optimal ist und diese Annahme dann zum Widerspruch führt. Um das zu erreichen wird gezeigt, dass man eine bessere Lösung erhalten würde, wenn man die nicht optimale Lösung ausschneidet und eine optimale dafür einfügt.
Raum der Teilprobleme charakterisieren
Wie gesagt ist es bei der Charakterisierung des Raumes der Teilprobleme vorteilhaft, diesen zunächst so klein wie möglich zu halten. Später kann man diesen auch noch erweitern, falls dies notwendig ist.
Beim Rucksackproblem bestand der Raum der Teilprobleme aus optimal gepackten 'Teil-Rucksäcken' die eine geringere Kapazität besaßen, als der für die Gesamtlösung betrachtete Rucksack. Da diese Lösung gut funktionierte bestand keine Notwendigkeit den Raum der Teilprobleme weiter zu verallgemeinern.
Wie man an späteren Beispielen aber noch sehen wird, ist es nicht immer so leicht eine optimale Teilstruktur festzulegen. Diese variiert in den verschiedenen Problemgebieten zum Einen in der Anzahl der Teilprobleme die innerhalb der optimalen Lösung des Ausgangsproblems verwendet werden, zum Anderen aber auch in der Zahl der Auswahlmöglichkeiten bei der Entscheidung, welche Teilprobleme in einer optimalen Lösung verwendet werden. Dabei wird der Aufwand zur Lösung eines Problems, durch die Multiplikation dieser beiden Faktoren ermittelt.
Betrachten wir dazu noch einmal das Rucksackproblem, erkennen wir, dass sich dadurch unsere Aufwandsbetrachtung der Iterativen Berechnung bestätigt. Dabei entspricht die Kapazität des Rucksacks der Anzahl der Teilprobleme und die Anzahl der Gegenstände
den Auswahlmöglichkeiten, die beim befüllen eines Rucksackes mit einer bestimmten Kapazität zu treffen sind. Das führt uns wie bereits bekannt zu einem Aufwand von
. Dabei ist zu berücksichtigen, dass sich der Aufwand durch rekursive Berechnung mit memoizing im Allgemeinen verringert, da nur die Teilprobleme berechnet werden, die auch wirklich zur Lösung benötigt werden und Mehrfachberechnungen entfallen.
Ungewichteter einfacher Pfad
Das nachfolgende Beispiel zum ungewichteten, einfachen Pfad, soll verdeutlichen, dass es nicht vorteilhaft ist eine optimale Teilstruktur anzunehmen, wenn diese nicht vorhanden ist. Dabei betrachten wir das Problem des ungewichteten, kürzesten Pfades und das des ungewichteten, längsten, einfachen Pfades. Bei beiden ist ein gerichteter Graph und Knoten
gegeben.

Bei dem Problem des ungewichteten, kürzesten Pfades suchen wir einen Pfad von nach
mit der minimalen Anzahl von Kanten. Dabei können wir auch
vorraussetzen. Weiterhin muss jeder Pfad
von
nach
auch einen dazwischenliegenden Knoten
enthalten, der selbstverständlich auch
oder
sein kann. Mit dieser Feststellung können wir den Pfad
in die Teilpfade
und
zerlegen. Dabei muss die Summe der Anzahl der Kanten in
und
gleich der Anzahl der Kanten in
sein. Nun nehmen wir an, dass wenn
ein optimaler Pfad von
nach
ist, dann ist
auch ein optimaler Pfad von
nach
. Dies lässt sich wiederum sehr einfach mit der 'Cut & Paste - Methode' beweisen. Das heißt wenn wir
ausschneiden und einen anderen Pfad
dafür einfügen könnten, um einen Pfad
mit weniger Kanten als
zu erhalten, würde dass der optimalen Eigenschaft von
wiedersprechen. Dasselbe gilt natürlich analog für
.
Im konkreten Beispiel kann man natürlich am besten erkennen, dass ein optimaler Pfad von
nach
in
aus den Teilpfaden
und
besteht und dass diese ebenfalls optimal sein müssen.
Betrachten wir nun das Problem des ungewichteten, längsten, einfachen Pfades. Was beim Problem des kürzesten Pfades fast offensichtlich ist, nämlich, dass es sich um einfache Pfade handeln muss, da jeder Zyklus nicht zu einer optimalen Lösung gehören kann; muss hier als zusätzliche Einschränkung dienen, da der längste Pfad sonst unendlich viele Zyklen enthalten würde. Natürlich ist es verlockend anzunehmen, dass dieses Problem ebenfalls optimale Teilstruktur aufweist. Dies ist jedoch gerade nicht der Fall. Unterteilt man den Pfad Analog zum vorhergehenden Problem in die Teilprobleme
und
, so muss man feststellen, dass die Teilprobleme ihrerseits nicht optimal sind.
Als Beispiel betrachten wir wieder den Pfad von nach
in
. Man kann erkennen, dass ein längster, einfacher Pfad
, unterteilt werden kann in die Teilprobleme
und
. Dabei sind die Teilprobleme jedoch keinesfalls optimal, da der längste, einfache Pfad von
nach
nicht
ist, sondern
. Tatsächlich lässt sich für dieses Problem auch keine optimale Teilstruktur finden. Somit wurde gezeigt, dass es besser ist keine optimale Teilstruktur anzunehmen, wenn diese nicht vorhanden ist.
Beispiele
Fibonacci-Zahl
ohne memoizing
mit memoizing
Rundreiseproblem
Optimalitätsbedingung
Auch für das Rundreiseproblem lässt sich sehr schnell eine Lösung mit Hilfe dynamischer Programmierung finden. Dabei wollen wir zunächst die Optimalitätsbedingung prüfen.
Wir stellen fest, dass eine Rundreise die in der Stadt beginnt, alle anderen Städte genau einmal besucht und dann wieder in
endet, unterteilt werden kann in den direkten Weg von
nach einer Stadt
und der weiteren Rundreise durch alle Städte aus
die wieder in
endet. Dabei ist anzunehmen, dass bei einer optimalen Gesamtlösung, der Weg von
nach
wieder optimal sein muss. Das lässt sich wieder sehr einfach mit dem bereits bekannten Widerspruchsbeweis bestätigen.
Rekursive Beschreibung der Lösung
Mit unseren Überlegungen erhalten wir somit schnell eine rekursive Beschreibung des minimalen Gesamtwegs :
Sind alle Städte besucht, geht man von der aktuellen Stadt zurück nach
, sonst suchen wir den kürzesten verbleibenden Rundweg.
Oder in mathematischer Notation:
Aufwandsbetrachtung
Die Tabelle zum speichern der Zwischenlösungen, die beim iterativen Vorgehen entsteht, besitzt die Dimensionen Spalten (
) für die Städte und
Zeilen für alle möglichen Städtemengen (also die Potenzmenge
).
Bei der Minimumbildung ist die Anzahl der Summen wiederum durch
bestimmt und benötigt somit einen Aufwand von
.
Somit ergibt sich mit der Anzahl der Tabellenfelder ein Aufwand von
.
Implementierung
Als Beispiel verwenden wir die Entfernungsmatrix E2 aus Verzweigen und Beschränken (siehe Abschnitt 6.3 im Buch [ Ch. Wagenknecht: Algorithmen und Komplexität]).
Die rekursive Implementierung mit Java fällt nun nicht sonderlich schwer, da sie sich direkt aus der rekursiven Vorschrift ableiten lässt.
Der obige Aufruf der Prozedur mit den Parametern (die erste Stadt) und
(die Liste der anderen Städte) liefert uns das erwartete Ergebnis
.
Aufgaben
Die Lösungen zu den Aufgaben sind teilweise schon im Wiki enthalten, wurden teilweise in der Vorlesung erzählt und/oder sind als Download bei den Files zu erhalten.
Desweiteren können die Aufgaben auch live im Wiki bearbeitet werden, dabei werden die Lösungen für den eingeloggten Benutzer gespeichert (nach dem Klick auf Ausführen).
Dabei ist es empfehlenswert, die Aufgaben zunächst lokal mit Hilfe einer IDE wie Netbeans oder Eclipse zu testen, bevor man diese ins Wiki übernimmt. Es kann auch vorkommen, dass gerade bei den Fibonacci-Zahlen in bestimmten Browsern Probleme auftreten, da nicht genug Speicher für die Java-Umgebung bereitgestellt wird. In diesem Fall sollten die Aufgaben auch lieber lokal getestet werden.
Fibonacci
Implementieren Sie verschiedene Versionen von der Fibonacci-Funktion.
Mithilfe dieser Funktion kann man sehr schnell erkennen wie dynamische Programmierung/Optimierung funktioniert und auch welchen Gewinn man davon hat.
ohne Memo rekursiv
Implementieren Sie diese Funktion anhand der oben gegeben mathematischen Gleichung ohne Memoizing.
Quelltext überprüfen:
mit Memo rekursiv
Die 'Standart-Funktion' wird je nach Rechnenleistung bei fib(>70) praktisch unlösbar.
Deswegen sollen Sie nun die Funktion so erweiteren, das man noch fib von 200 berechnen kann. Als kleiner Tipp, nutzen Sie Memoizing und sein sie sich gegenüber ehrlich und probieren es erst, bevor Sie nach schauen. ;)
Da bei der Berechnung großer Fibonacci-Zahlen extrem große Werte entstehen, verwenden wir hier die Java Klasse java.math.BigInteger, die nach oben nicht beschränkt ist (maximal durch den Speicher), was die Größe der Zahlen betrifft. Deshalb ist es sinnvoll sich zunächst, zumindest mit den grundlegenden Operationen dieser Klasse vertraut zu machen. Dazu wird die Java-API empfohlen, zu finden unter: API:BigInteger. Zudem kann es vorteilhaft sein, sich noch einmal mit den Methoden der java.util.HashMap vertraut zu machen, damit die Methodennamen keine Schwierigkeiten bereiten. Die API dazu findet ihr hier: API:HashMap.
Quelltext überprüfen:
Iterative Lösung von Fib
Wir haben bis jetzt schon viel über Fibonacci geredet, jedoch immer nur über die rekursive Lösung. Warum nicht einmal Iterativ lösen?
Deswegen mal die Aufgabe zur Iterativen Lösung von Fib.
Was können Sie über das Speicherverhalten, Stackverhalten und auch den Aufwand sagen?
Quelltext überprüfen:
Zusatz: mit Memo und fast konstantem Speicheraufwand
Optimieren Sie nun die vorhergehende Version so, das nun auch noch Fib von 5000 berechnet werden kann. Sollten Sie dieses Problem schnell behoben haben, bauen Sie diese Funktion noch so um, dass nun auch fib von 50000 berechnet werden kann.
Warum tritt in Java der StackOverflowError auf?
Was können Sie über das Speicherverhalten von Fib sagen?
Diese Aufgaben könnte man in kleinen Diskussionsrunden klären.
Quelltext überprüfen:
Matritzen-Kettenmultiplikation
Schreiben Sie eine Funktion, die die optimale Klammerung der Matritzen-Kettenmultiplikation vornimmt, mit dem Ziel, dass die geringsten Operationen bei der Multiplikation entstehen. Sie können dazu die unten angegeben Methode verwenden zum erzeugen von Matrizen mit Zufallswerten.
Beispiel: der Aufruf generateMatrix(4, 5, 10); liefert eine Matrix mit 4 Zeilen, 5 Spalten und Werten zwischen 0 und 9, repräsentiert als int[zeilen][spalten].
Als Hilfestellung sind die Liste zum speichern der Matrizen und die Memoliste schon vorgegeben. Diese ist vom Typ HashMap<Integer,HashMap<Integer,Integer>>. Ebenso kann man die HashMap kListe verwenden zum speichern der Position, an der die Kette bei einer optimalen Klammerung aufgespalten wird.
Hier nochmal die rekursive Formulierung des Algorithmus in mathematischer Notation:
Quelltext überprüfen:
Versuchen Sie auch die optimale Klammerung für eine Kette per Hand mithilfe der naiven Methode zu finden.
Sie werden feststellen, dass es bereits bei 4 Matrizen schon einen erheblichen Aufwand bedeutet.
Zusatz: Ausgabe der optimalen Klammerung
Verwenden Sie die kListe und schreiben sie eine Methode, die die optimale Klammerung ausgibt.
Beispiele aus der Vorlesung
Desweiteren können Sie gerne die Aufgaben aus der Vorlesung noch lösen, auch dazu können Sie uns fragen.
Hilfe?
Fragen Sie einfach die Übungsleiter Ullrich oder Baum.
Files
Vortragsfolien
 | Vortrag-AuK.pdf (0.7 MB) |
Lösungen zu den Aufgaben
 | DynProgrammierung_Loesung.zip (0.1 MB) |
Lösungen im Wiki: Lösungen_Dynamisches_Programmieren
Links
F# Compiler Download (auch für Mono)
Literatur
- Th. H. Cormen, Ch. E. Leiserson, R. Rivest, C. Stein: Algorithmen - Eine Einführung, 2.Auflage, Oldenbourg Wissenschaftsverlag GmbH 2007, ISBN 978-3-486-58262-8
- Gessner, Wacker: Dynamische Optimierung - Einführung-Modelle-Computerprogramme, 1.Auflage, Carl Hanser Verlag 1972, ISBN 3-446-11539-0
- Ch. Wagenknecht: Algorithmen und Komplexität, 1.Auflage, Carl Hanser Verlag 2003, ISBN 3-446-22314-2
- A. Iwainsky: Dynamische Optimierung - Gegenstand-Methoden-Möglichkeiten, 1.Auflage, VEB Verlag Technik Berlin 1984
- J. Hinrichsen: Branch- and Bound-Verfahren zur Lösung des Rundreiseproblems, Vandenhoeck & Ruprecht Göttingen 1975, ISBN 3-525-12432-5
- S. Wolfgang, U. Gerhard: Dissertation Duale Entartung in der lineare Optimierung, Transportproblem mit zusätzlichen Nebenbedingungen und Rundreiseproblem TU Dresden und Bergakademie Freiberg, 21.02.1975
- http://www.matheprisma.uni-wuppertal.de/Module/Rekurs/index.htm
- http://www.dasautoblog.com/2007/06/interessantes_w.html