Durchläufe durch Graphen WS13-14
Aus ProgrammingWiki
Inhaltsverzeichnis |
Einleitung
Für einen Graphendurchlauf bzw. das Durchsuchen eines Graphen gibt es viele Verfahren und Darstellungsmethoden, die vor allem die Basis für Graphenalgorithmen bilden. Beim Durchsuchen werden systematisch alle Kanten eines Graphen verfolgt und die Knoten aufgesucht. Wird ein Durchsuchungsalgorithmus auf einen Graphen angewandt, kann dieser Aufschluss über die Struktur dessen geben. Beispiele für solche Durchsuchungsalgorithmen sind die Tiefen- und Breitensuche, die in der Vorlesung zur Systematischen Suche schon kurz behandelt worden sind. Einfach weiterentwickelte Durchsuchungsalgorithmen werden als Graphenalgorithmen bezeichnet.
Hinweis: Obwohl es sich eigentlich um einen Graphendurchlauf handelt, wird der Begriff "Suche" häufiger benutzt, da er sich von den englischen Bezeichnungen DFS und BFS (depth-first search und breadth-first search) ableitet.
Breitensuche
Die Breitensuche beschäftigt sich mit dem systematischen Suchen in einem Graphen. Sie ist einer der einfachsten
Algorithmen dieser Art.
Wir definieren einen Graphen $G = (V,E)$. Dieser hat einen Startknoten $s$, von welchem aus die Breitensuche beginnt.
Es werden alle Knoten erforscht, die von $s$ aus zugänglich sind. So entsteht ein Breitensuchbaum mit der Wurzel $s$. Außerdem berechnet der Algorithmus die Abstände der von $s$ aus erreichbaren Knoten. Er arbeitet sowohl in gerichteten als auch ungerichteten Graphen.
Ihren Namen verdankt die Breitensuche der Tatsache, dass die Entdeckung der Knoten sich gleichmäßig über die gesamte Breite erstreckt.
Das bedeutet, dass der Algorithmus erst alle Knoten mit dem Abstand $k$ von $s$ entdeckt bevor ein Knoten mit $k+1$ bekannt wird.
Um die Breitensuche zu verdeutlichen, werden die Farben weiß, grau und schwarz verwendet.
An Anfang sind alle Knoten weiß. Wenn ein Knoten entdeckt wird, wird er grau und kann schließlich schwarz werden.
Es gilt, wenn ein Knoten schwarz oder grau ist, dann ist er bereits entdeckt worden.
Schwarze Knoten können mit schwarzen oder grauen benachbart sein. Graue Knoten können auch mit weißen benachbart sein, da sie die Front zwischen bereits erforschten und unerforschten Knoten darstellen.
Um Prozedur BFS (Breadth-first search) durchzuführen, muss der eingegebene Graph durch Adjazenzlisten dargestellt werden.

BFS ($G,s$)
1 for alle Knoten $u \in V[G]$ - {$s$}
2 $\;\;\;\;\;$ do $farbe[u] \leftarrow$ WEISS
3 $\;\;\;\;\;\;\;\;\;\;$ $d[u] \leftarrow \infty$
4 $\;\;\;\;\;\;\;\;\;\;$ $\pi[u] \leftarrow$ NIL
5 $farbe[s] \leftarrow$ GRAU
6 $d[s] \leftarrow$ 0
7 $\pi[s] \leftarrow$ NIL
8 $Q \leftarrow \empty$
9 ENQUEUE($Q,s$)
10 while $Q \ne \empty$
11 $\;\;\;\;\;$ do $u \leftarrow$ DEQUEUE($Q$)
12 $\;\;\;\;\;\;\;\;\;\;$ for alle $v \in Adj[u]$
13 $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ do if $farbe[v]$ = WEISS
14 $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ then $farbe[v] \leftarrow$ GRAU
15 $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ $d[v] \leftarrow d[u] + 1$
16 $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ $\pi[v] \leftarrow u$
17 $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ ENQUEUE($Q,v$)
18 $\;\;\;\;\;\;\;\;\;\;$ $farbe[u] \leftarrow$ SCHWARZ
Tiefensuche
Die Tiefensuche beschreibt, wie der Name bereits andeutet, das systematische Vordringen in die "Tiefe" eines Graphen und wird häufig als Unterroutine in einem anderen Algorithmus verwendet.
Man startet von einem beliebigen Startknoten $u \in V(G)$ aus und folgt einer benachbarten Kante zum nächsten Knoten. Dabei werden die ungeprüften Kanten des zuletzt entdeckten Knotens untersucht und man gelangt zu weiteren unbesuchten Knoten. Ist ein Blattknoten erreicht, endet der Kantenzug und alle bis dahin entdeckten Knoten wurden markiert. "Die Suche kehrt um", d.h. man folgt dem Kantenzug zurück zu einem Knoten, der noch ungeprüfte Kanten und demnach unbesuchte Knoten besitzt.
Dieser Vorgang wiederholt sich, bis alle vom ursprünglichen Startknoten $u$ aus erreichbaren Knoten entdeckt wurden.
Sollten unentdeckte Knoten übrig bleiben, wird einer von ihnen als neuer Startknoten festgelegt und die Suche wiederholt, bis alle Knoten entdeckt sind.
Durch die verschiedenen Startknoten können mehrere Bäume entstehen, die so genannten Tiefensuchbäume. Mehrere Tiefensuchbäume bilden einen Tiefensuchwald.
Wie bei der Breitensuche gelten die folgenden Markierungen für die Zustände der Knoten:
- WEISS = unentdeckte Knoten
- GRAU = entdeckte Knoten
- SCHWARZ = abgearbeitete Knoten
Ein weiteres Merkmal der Tiefensuche ist, dass sie jeden Knoten $u$ mit zwei Zeitstempeln versieht. Die Zeitstempel sind hilfreich bei Überlegungen zum Verhalten der Tiefensuche und werden in vielen Graphenalgorithmen verwendet.
Der erste Zeitstempel $d[u]$ vermerkt, wann $u$ entdeckt (und demnach grau gefärbt) wurde. Der zweite Stempel $f[u]$ zeichnet auf, wann $u$ abgearbeitet (und schwarz gefärbt) wurde, folglich wurde das Prüfen der Adjazenzlsite von $u$ beendet.
Für jeden Knoten $u$ gilt:
- $d[u]$ < $f[u]$.
Die Prozedur DFS beschreibt den grundlegenden Algorithmus der Tiefensuche. Er kann auf gerichtete sowie ungerichtete Graphen angewendet werden.
Anmerkung: Die globale Variable $zeit$ wird für die Zeitstempel verwendet. Und (wie bei der Breitensuche) wird das Vorgängerattribut $\pi[v]$ auf $u$ gesetzt, wenn ein Knoten $v$ entdeckt wird beim Durchsuchen der Adjazenzliste eines bereits entdeckten Knotens $u$.

DFS ($G$)
1 for alle Knoten $u\in V[G]$
2 $\;\;\;\;\;$ do $farbe[u]$ $\leftarrow$ WEISS
3 $\;\;\;\;\;\;\;\;\;\;$ $\pi[u]$ $\leftarrow$ NIL
4 $zeit$ $\leftarrow$ 0
5 for alle Knoten $u\in V[G]$
6 $\;\;\;\;\;$ do if $farbe[u]$ = WEISS
7 $\;\;\;\;\;\;\;\;\;\;$ then DFS-VISIT($u$)
DFS-VISIT ($u$)
1 $farbe[u]$ $\leftarrow$ GRAU $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ weißer Knoten $u$ entdeckt
2 $zeit \leftarrow zeit+1$
3 $d[u] \leftarrow zeit$
4 for alle$ v \in Adj(u)$ $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ verfolge Kante ($u,v$)
5 $\;\;\;\;\;$ do if $farbe[v]$ = WEISS
6 $\;\;\;\;\;\;\;\;\;\;\;$ then $\pi[v] \leftarrow u$
7 $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ DFS-VISIT($v$)
8 $farbe[u] \leftarrow$ SCHWARZ $\;\;\;\;\;\;\;\;\;\;\;\;\;\;\;$ $u$ abgearbeitet
9 $f[u] \leftarrow zeit \leftarrow zeit+1$
Der Algorithmus überprüft in Zeile 5-7 der Reihe nach alle Knoten aus $V$ und wendet die rekursive Prozedur DFS-VISIT an, wenn ein weißer Knoten gefunden wurde. Jedes Mal, wenn DFS-VISIT($u$) in Zeile 7 ausgeführt wird, wird der Knoten $u$ Wurzel eines neuen Baumes des Tiefensuchwaldes.
In Zeile 4 von DFS-VISIT werden nun alle benachbarten Knoten $v$ von $u$ untersucht und man sagt, die Kante ($u,v$) wird sondiert. Nachdem alle austretenden Kanten aus $u$ sondiert wurden, wird der Knoten schwarz gefärbt. Ist der Algorithmus zu Ende, besitzt jeder Knoten eine Entdeckungszeit $d[u]$ und eine Endzeit $f[u]$.
Bemerkung: Die Ergebnisse der Tiefensuche hängen von der Reihenfolge der untersuchten Knoten ab, führen aber in der Praxis zu keinerlei Problemen, da jedes Resultat effektiv genutzt kann.
Die Tiefensuche hat viele wichtige Eigenschaften vorzuweisen. Eine nennenswerte ist die Klammerstruktur der Entdeckungs- und Endzeiten. Dabei wird die Entdeckung eines Knoten $u$ durch eine linke Klammer "($u$" und seine Abarbeitung durch eine rechte Klammer "$u$)" dargestellt, sodass ein wohlgeformter Ausdruck entsteht.
Klassifikation der Kanten
Eine weitere Eigenschaft der Tiefensuche ist die Klassifizierung der Kanten eines Eingabegraphen $G$, die uns hilft weitere Informationen über den Graphen einzuholen. Zum Beispiel ist ein gerichteter Graph genau dann azyklisch, wenn die Tiefensuche auf ihn keine "Rückwärtskanten" liefert. Dieser Sachverhalt ist für das Topologische Sortieren von Bedeutung.
Es lassen sich die folgenden Kantentypen definieren:
- Baumkanten sind Kanten im Tiefensuchwald. Die Kante ($u,v$) ist eine Baumkante, falls $v$ bei der Sondierung der Kante ($u,v$) entdeckt wurde.
- Rückwärtskanten sind Kanten ($u,v$), die einen Knoten $u$ mit einem Vorfahren $v$ im Tiefensuchbaum verbinden. Schlingen in gerichteten Graphen zählen auch dazu.
- Vorwärtskanten sind Kanten ($u,v$), die einen Knoten $u$ mit einem Nachfahren $v$ im Tiefensuchbaum verbinden.
- Querkanten sind alle übrigen Kanten. Sie können zwischen Knoten verschiedener und gleicher Tiefensuchbäume verlaufen, wobei im letzten Fall ein Knoten nicht der Vorfahre des anderen sein darf.
Im weiteren lässt sich daraus schlussfolgern, dass man jede Kante ($u,v$) anhand der Farbe des Knoten $v$ klassifizieren können, wenn diese erstmals sondiert wird.
- Ist der Knoten $v$ weiss, handelt es sich um eine Baumkante.
- Bei einem grauen Knoten ist es eine Rückwärtskante.
- Schwarz deutet auf eine Vorwärts- oder Querkante hin.
Hinweis: Um Vorwärts- und Querkanten zu unterscheiden, bezieht man sich auf folgenden Sachverhalt:
- Eine Kante ($u,v$) ist im Falle $d[u]$ < $d[v]$ eine Vorwärtskante und im Falle $d[u]$ > $d[v]$ eine Querkante.
Das folgende Beispiel a) zeigt das Ergebnis einer Tiefensuche auf einen gerichteten Graphen. Die Zeitstempel sind in den Knoten eingetragen und die Kantentypen sind gekennzeichnet. In b) ist die Klammerstruktur des Graphen zu sehen. Die Zeitspanne zwischen Entdeckung und Abarbeitung eines Knoten wird durch ein Rechteck symbolisiert. Man erkennt, dass Intervalle vollständig in einem anderen eingeschlossen sind, d. h. der Knoten mit dem kleineren Intervall ist Nachfolger des Knoten mit dem größeren Intervall. In c) sehen wir nochmals den Graphen mit allen Baum- und Vorwärtskanten, die abwärts gerichtet sind, und allen aufwärts gerichteten Rückwärtskanten.
 a) Beispielgraph |
 b) Klammerstruktur des Graphen |
 c) Graph mit allen Kanten |
Vergleich von Tiefen- und Breitensuche
| Tiefensuche | Breitensuche | |
| Anwendung | Topologisches Sortieren Bestimmung von SCCs |
Ermittlung kürzester Pfade |
| Speicherverbrauch | gering | hoch |
| Laufzeit | $\mathcal{O}\: (|V| + |E|)$ | $\mathcal{O}\: (|V| + |E|)$ |
Topologisches Sortieren
Bei der topologischen Sortierung geht es um Dinge, bei denen die Reihenfolge eine Rolle spielt. Man kann beispielsweise kein Dach ohne tragende Wände bauen und ebenfalls sollte man die Socken vor den Schuhen anziehen.
Mit Hilfe der Tiefensuche lässt sich topologisches Sortieren bewerkstelligen. Hierfür ist ein gerichteter azyklischer Graph notwendig. Dieser wird auch "DAG" (directed acyclic graph) genannt.
Formell lässt sich sagen, dass eine topologische Sortierung dann vorliegt, wenn es einen DAG $G = (V,E)$ gibt, dessen Knoten sich in einer linearen Anordnung befinden.
Weiterhin müssen sie die Eigenschaft haben, dass $u$, in der Anordnung, vor $v$ liegt. Das gilt nur, wenn in $G$ eine Kante ($u,v$) gibt.
In einer topologischen Sortierung kann man den dargestellten Graphen als eine horizontale Anordnung seiner Knoten verstehen, die gerichtet von links nach rechts zeigen.
TOPOLOGICAL-SORT($G$)
1 rufe DFS($G$) zur Berechnung der Endzeiten $f[v]$ für alle Knoten $v$ auf
2 füge jeden abgearbeiteten Knoten an den Kopf einer verketteten Liste ein
3 return die verkettete Liste der Knoten


Starke Zusammenhangskomponenten

Eine weitere Anwendung der Tiefensuche neben dem Topologischen Sortieren ist die Zerlegung eines gerichteten Graphen in seine starken Zusammenhangskomponenten. Viele Algorithmen, die mit gerichteten Graphen arbeiten, zerlegen diesen zuerst, um dann jede starke Zusammenhangskomponente einzeln zu durchlaufen. Die Lösungen werden am Ende entsprechend der Strukturverbindungen zwischen den Komponenten zusammengeführt.
Eine starke Zusammenhangskomponente ist eine maximale Menge $C \subseteq V$ von Knoten eines gerichteten Graphen $G = (V,E)$. Für jedes Paar $u,v$ aus $C$ sind die Knoten von dem jeweils anderen aus erreichbar.
Der Algorithmus STRONGLY-CONNECTED-COMPONENTS ermittelt die starken Zusammenhangskomponenten eines Graphen $G$, indem er einmal eine Tiefensuche auf $G$ und eine auf $G^{T}$ anwendet. $G^{T}$ ist der zu $G$ transponierte Graph und ist wie folgt definiert: $G^{T}$ = $(V,E^{T})$ mit $E^{T}$ = {($u,v$) : ($v,u) \in E$}. Demnach besteht die Kantenmenge $E^{T}$ aus den Kanten von $G$ mit umgekehrter Richtung. Weil $G$ und $G^{T}$ die gleichen starken Zusammenhangskomponenten haben, sind die Knoten $u$ und $v$ genau dann voneinander erreichbar, wenn sie in $G^{T}$ voneinander erreichbar sind.
STRONGLY-CONNECTED-COMPONENTS($G$)
1 rufe DFS($G$) zur Berechnung der Endzeiten $f[u]$ für alle Knoten $u$ auf
2 konstruiere $G^{T}$, indem bei jeder Kante aus $G$ die Richtung umgekehrt wird
3 rufe DFS($G^{T}$) auf; die Knoten werden in der Reihenfolge nach fallender Endzeit $f[u]$ betrachtet
4 gib die Knotenmenge jedes in Zeile 3 entstandenen Baumes als separate starke Zusammenhangskomponente aus
Als Beispiel haben wir den gerichteten Graphen $G$ oben gegeben.
- Zuerst wenden wir die Tiefensuche auf $G$ an, um die Endzeiten zu berechnen und erzeugen alle Tiefensuchbäume.
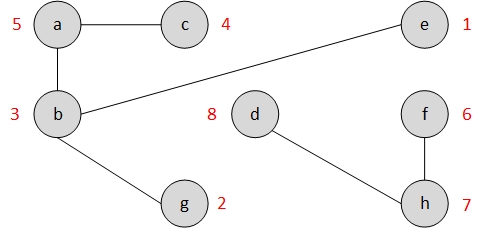
- Wir bilden einen inversen Graphen $G^{T}$ zu $G$.
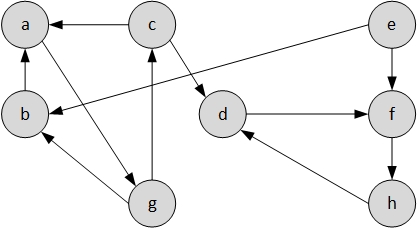
- Nun wenden wir die Tiefensuche auf $G_T$ an und beginnen mit dem Knoten mit der höchsten Nummmerierung.
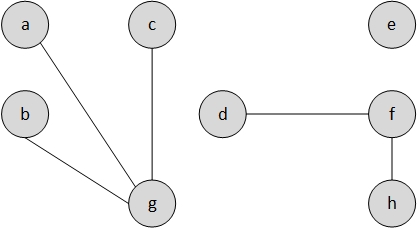
- Die Knotenmengen der entstandenen Bäume sind SCCs von $G$.
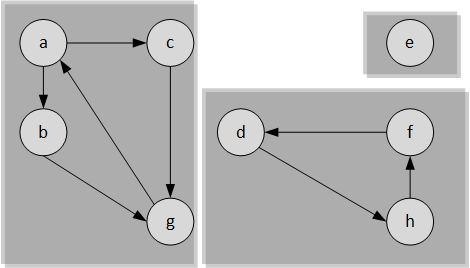




Mehrere starke Zusammenhangskomponenten $C_1, C_2,\ldots, C_k$ bilden einen Komponentengraphen $G^{SCC}$ = ($V^{SCC},E^{SCC}$), welcher auch ein DAG ist. Die Knotenmenge $V^{SCC}$ enthält einen Knoten $v_i$ für jede starke Zusammenhangskomponente $C_i$ von $G$. Die Kantenmenge $E^{SCC}$ setzt sich aus den gerichteten Kanten zwischen den einzelnen Komponenten zusammen. Die Kanten, deren indizierenden Knoten zur selben starken Zusammenhangskomponenten gehören, werden kontrahiert. Beispielsweise wäre ein Knoten von $G^{SCC}$ in unserem obigen Beispiel dann $abcg$.
Übungen
 | Aufgaben_Graphendurchläufe.pdf (0.2 MB) |
| Lösung_Graphendurchläufe.pdf (0.2 MB) |
Literaturverzeichnis
- Cormen, Thomas; Leiserson, Charles; Rivest, Ronald; Stein, Clifford: Algorithmen, eine Einführung; Oldenbourg Verlag, 2007
- Güting, Ralf Hartmut: Datenstrukturen und Algorithmen; B.G. Teubner Stuttgart, 1992
- http://wwwiti.cs.uni-magdeburg.de/iti_db/lehre/algds0506/handout2-9.pdf
- http://www.stormware-computer.de/script/kapitel_4_1.pdf
- http://whz-cms-10.zw.fh-zwickau.de/sibsc/lehre/ss10/ad/v13.pdf
- http://www.cs.hs-rm.de/~heimrich/Algorithmen%20&%20Datenstrukturen/Vorlesungen/vorlesung10.pdf